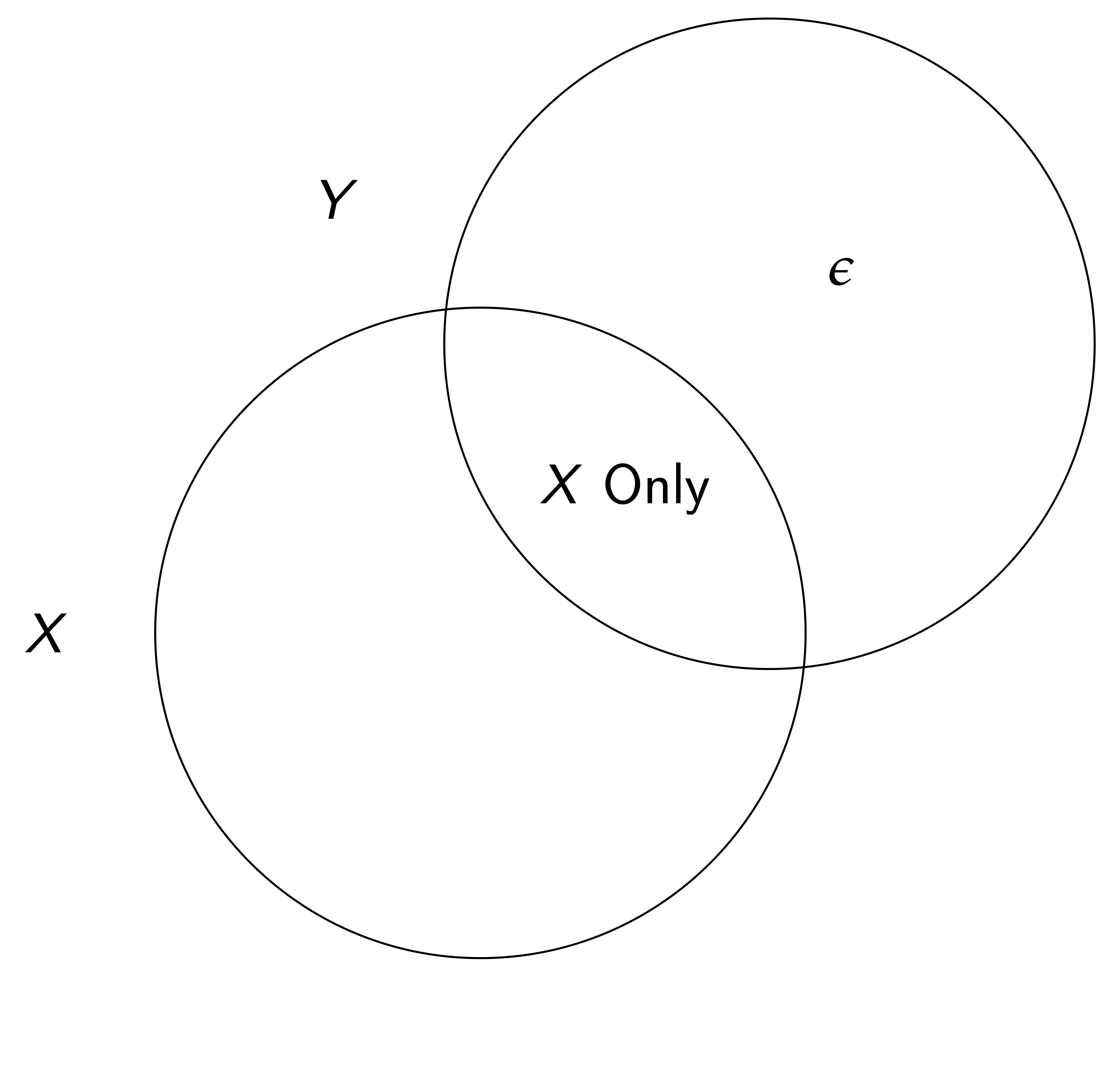
Autrement dit, si un élément x de X n’est pas orthogonal à \varepsilon, \widehat{\beta}_{MCO} est biaisé (notez qu’ici on parle de \beta le coef. univarié de x, pas du vecteur de tous les coefs.)
Supposons que nous puissions trouver une autre variable (instrumentale) qui satisfait
x = \gamma z + \tilde{X}\gamma_{\tilde{X}} + \mu \quad \text{où} \quad Cov[z,\varepsilon] = 0, \gamma \ne 0
Nous pouvons isoler la variation dans la détermination de x à travers z qui est non liée à la relation principale que nous étudions (l’effet de x sur y).
Introduction à la méthode des VI
Nous avons besoin de deux hypothèses pour une VI valide
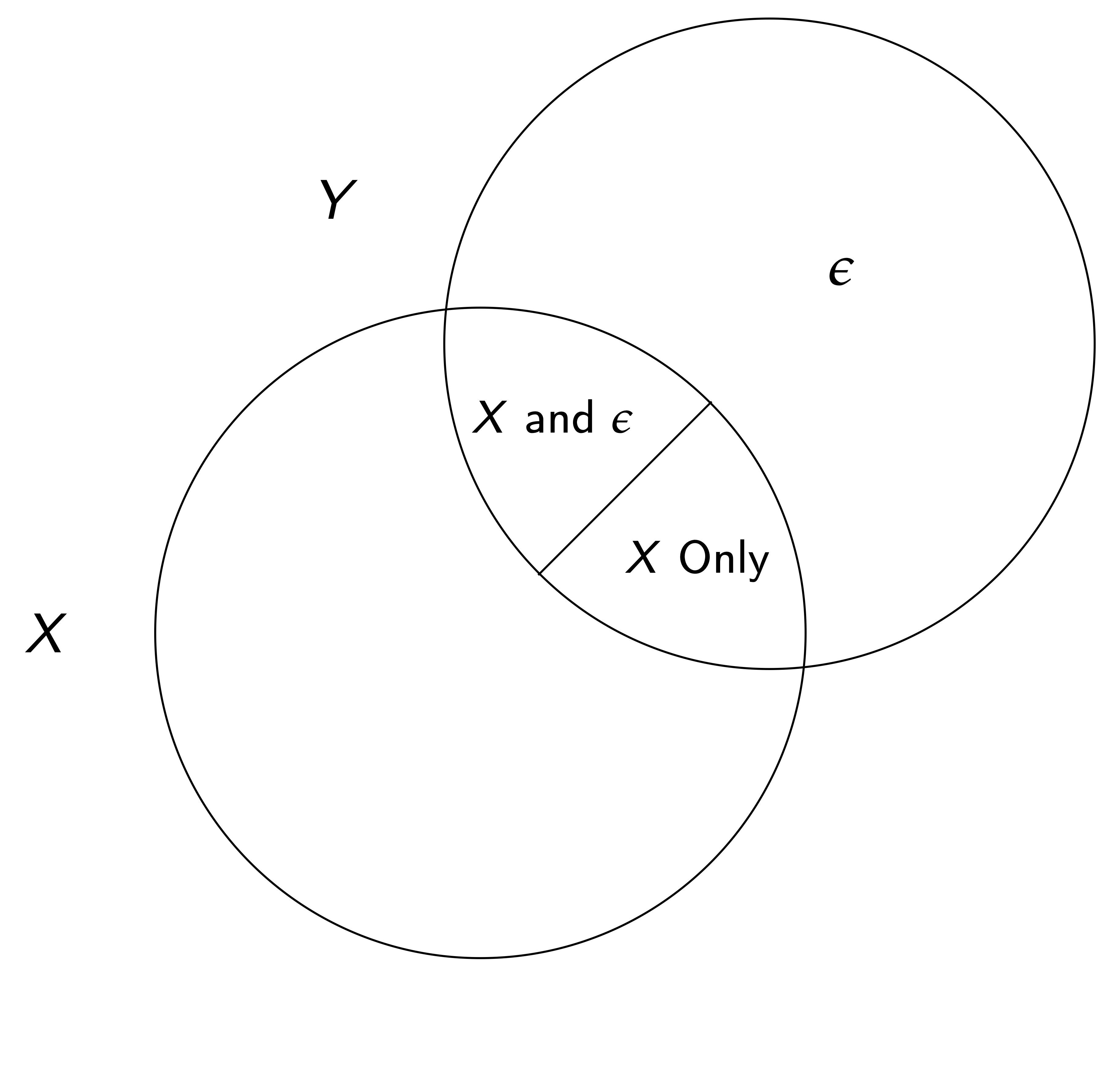
Pertinence — Il doit y avoir une corrélation entre z et xconditionnelle à toutes les autres variables dans un système c’est-à-dire \gamma \ne 0
Exclusion — La variable peut être exclue de l’équation principale d’intérêt.
Deux parties importantes à cette hypothèse :
La seule relation entre z et y passe par la relation de la première étape
Conditionnellement aux covariables (\tilde{X}), l’instrument est aussi bon que réparti aléatoirement
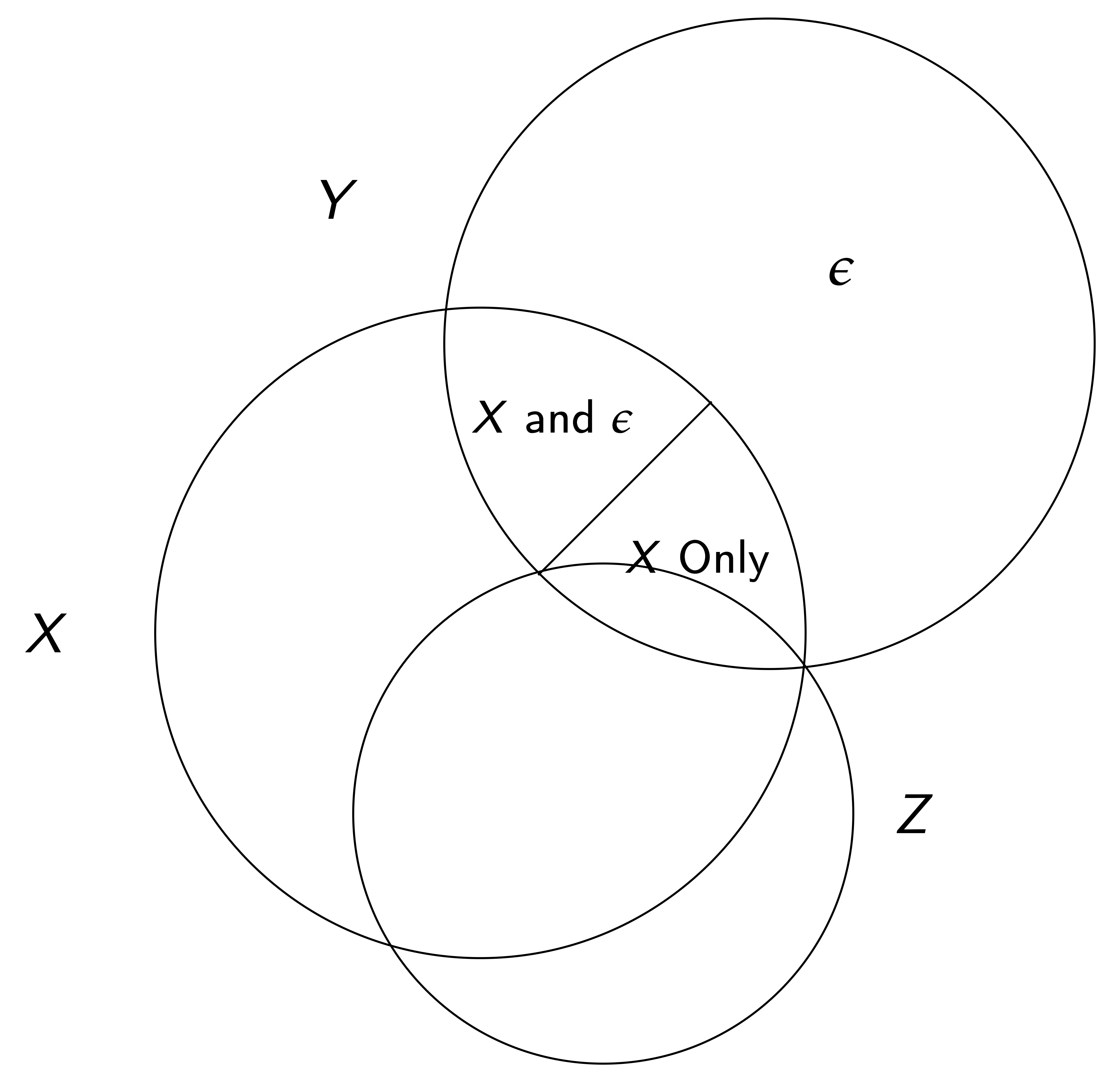
Variation et VI
Variation et VI
Variation et VI
Comment cela fonctionne-t-il ?
Généralement effectué comme une estimation MCO en deux étapes
Estimer la relation entre z et x (en incluant toutes les autres variables dans l’équation principale)
Estimer \hat{x} en utilisant les coefficients estimés
Estimer le modèle du deuxième étape avec \hat{x}
Peut également être estimé en tant que système GMM
Notez que les hypothèses d’identification impliquent que le coefficient VI est asymptotiquement cohérent
L’estimateur est biaisé dans des échantillons finis, mais nous y reviendrons plus tard
D’où viennent les bons instruments?
L’IV a été initialement développée comme une technique pour estimer des systèmes d’équations (par exemple, l’offre et la demande d’oranges)
Utiliser la pluie pour instrumenter l’offre afin d’isoler les perturbations dans la quantité et le prix le long d’une courbe de demande
Les bons instruments ont un lien économique crédible pour la pertinence et une raison logique d’exclusion
La pertinence peut être testée car il s’agit d’une corrélation partielle
L’exclusion ne peut pas être testée, elle doit donc être argumentée sur la base d’un raisonnement logique
Les (bons) instruments courants comprennent les événements physiques, les changements institutionnels, etc.
Les mauvais instruments courants incluent des variables retardées (lags) et des moyennes de groupe excluant un membre individuel
Restriction d’exclusion
L’hypothèse d’exclusion ne peut pas être testée
Nous n’observons jamais les vraies erreurs d’un modèle, donc nous ne pouvons pas tester si elles sont corrélées avec notre instrument
De plus, les résidus estimés seront toujours orthogonaux à toutes les covariables dans une régression, donc nous ne pouvons pas “tester” si une variable potentiellement endogène est corrélée avec l’erreur d’une régression
Les chercheurs doivent fournir des preuves soutenant que la restriction d’exclusion pourrait tenir
Les tests placebo peuvent être utiles
Peut-être y a-t-il une région ou une période où nous pensons qu’un effet ne devrait pas être présent
Y a-t-il d’autres résultats où les histoires de confusion auraient des implications qui peuvent être testées ?
Biais et VI
L’estimateur VI est cohérent, mais biaisé dans les échantillons finis vers l’estimateur MCO
Parce que la première étape est estimée (avec bruit), il y a un biais sauf si l’échantillon soit vraiment grand
Puisque (asymptotiquement) \widehat{\beta}_{2SLS} = \beta + \frac{Cov[\epsilon,z]}{Cov[x,z]}, dans des échantillons finis, nous divisons le biais potentiel par la force de l’instrument, donc il est vraiment important d’avoir un instrument fort
L’ajout d’instruments faibles aggrave le problème
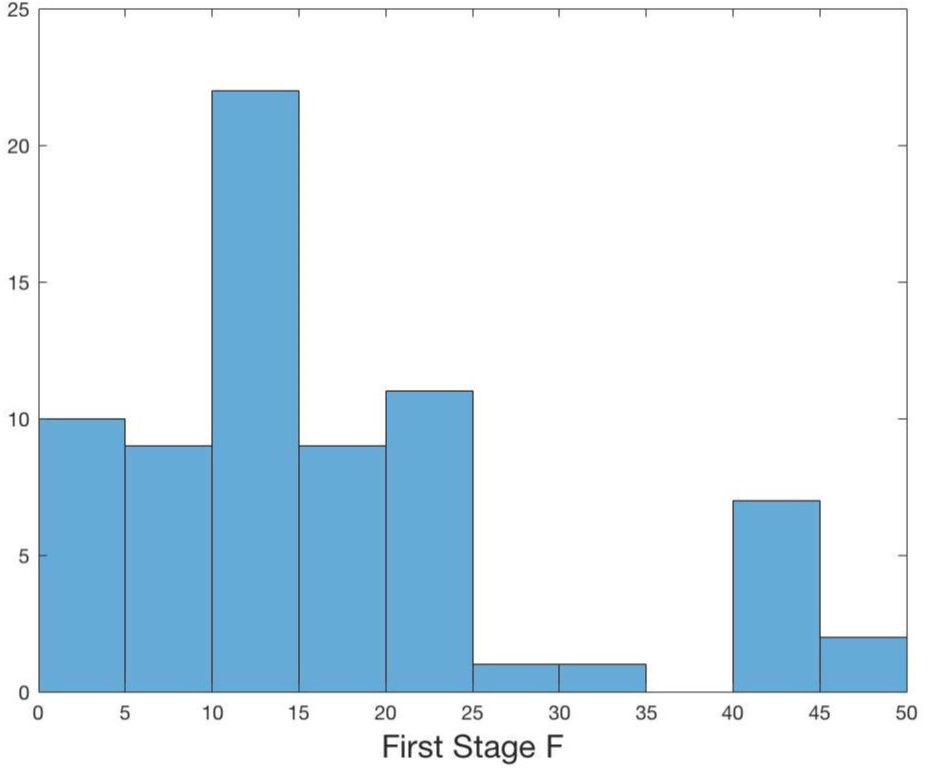
Plusieurs articles suggèrent d’avoir une statistique F pour la première étape sur l’instrument supérieure à 10 ou plus.
Les meilleures pratiques évoluent
Inférence avec des instruments faibles (mais valides)
L’imposition de filtres (comme un seuil de statistique F) peut induire des distorsions dans les spécifications/magnitudes rapportées
Les instruments faibles ne posent problème que lorsqu’il y a une violation de la restriction d’exclusion — les filtres excluront des cas de bons instruments qui ont une faible puissance — et identifieraient autrement des magnitudes causales utiles
Comme les seuils de p-value
Distribution des F-Statistiques dans les publications AER 2014–2018
Sur-identification
Considérez une seule variable endogène dans une équation. S’il y a plus d’un instrument pour la variable, elle est sur-identifiée. Dans ce cas, il y a un “test” pour montrer si un instrument par rapport à un autre instrument fournit des estimations différentes
MAIS ils pourraient tous être de mauvais instruments…
Exemple d’IV — Neige et Effet de Levier
Giroud et al. (2012) (GMSW) étudie si la réduction du surendettement améliore la performance des entreprises
Question importante, mais difficile de trouver une variation exogène de l’annulation de la dette
Les auteurs examinent les changements “inattendus” de la quantité de neige sur les stations de ski autrichiennes
Regardez au sein de l’ensemble des entreprises qui ont réalisé une restructuration de la dette pour essayer d’identifier celles qui étaient des défauts stratégiques — c’est-à-dire ces entreprises qui ont fait défaut malgré des circonstances “favorables”.
Histoire économique — ces entreprises qui avaient renégocié et avaient reçu une quantité inattendue de bonne neige étaient probablement sous-investies ou paresseuses, tandis que celles qui avaient de la mauvaise neige étaient plus susceptibles d’être des défauts de liquidité
Possible si les prêteurs ne peuvent pas s’engager ex-ante de manière crédible à une liquidation ex-post inefficace
Une alternative évidente est que les gestionnaires qui font défaut malgré une bonne neige sont de mauvais gestionnaires. Les auteurs tentent de résoudre ce problème.
GMSW
Notez que leur histoire ne concerne pas la quantité de neige, mais la neige inattendue
Le cadre économique plaide pour la pertinence
La restriction d’exclusion ((1) que conditionnellement aux covariables la variation est aléatoire et (2) que le soulagement de la dette stratégique est le seul canal en jeu) repose sur quelques points
L’analyse principale porte sur les entreprises en restructuration — donc l’analyse regarde au sein de l’ensemble des entreprises en restructuration et isole la variation de la manière dont la dette a été restructurée, donc les histoires alternatives doivent expliquer la variation au sein de ces entreprises
Les auteurs contrôlent pour le montant de neige (et celle-ci a un effet dans la direction prévue), donc les explications alternatives ne peuvent pas porter sur la quantité de neige
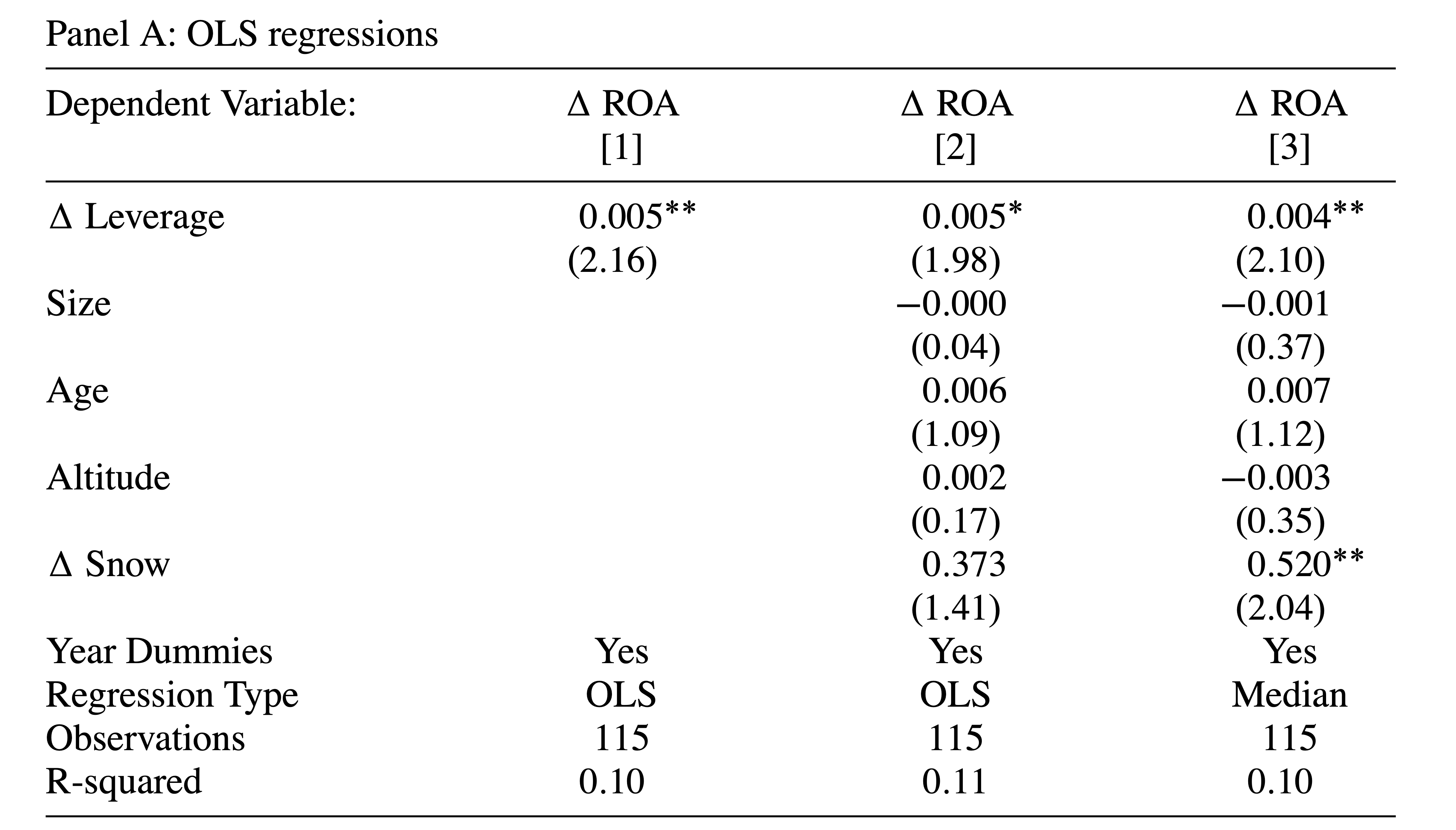
Les auteurs commencent d’abord par des régressions MCO — ils constatent qu’une augmentation de l’effet de levier est corrélée avec une augmentation du ROA
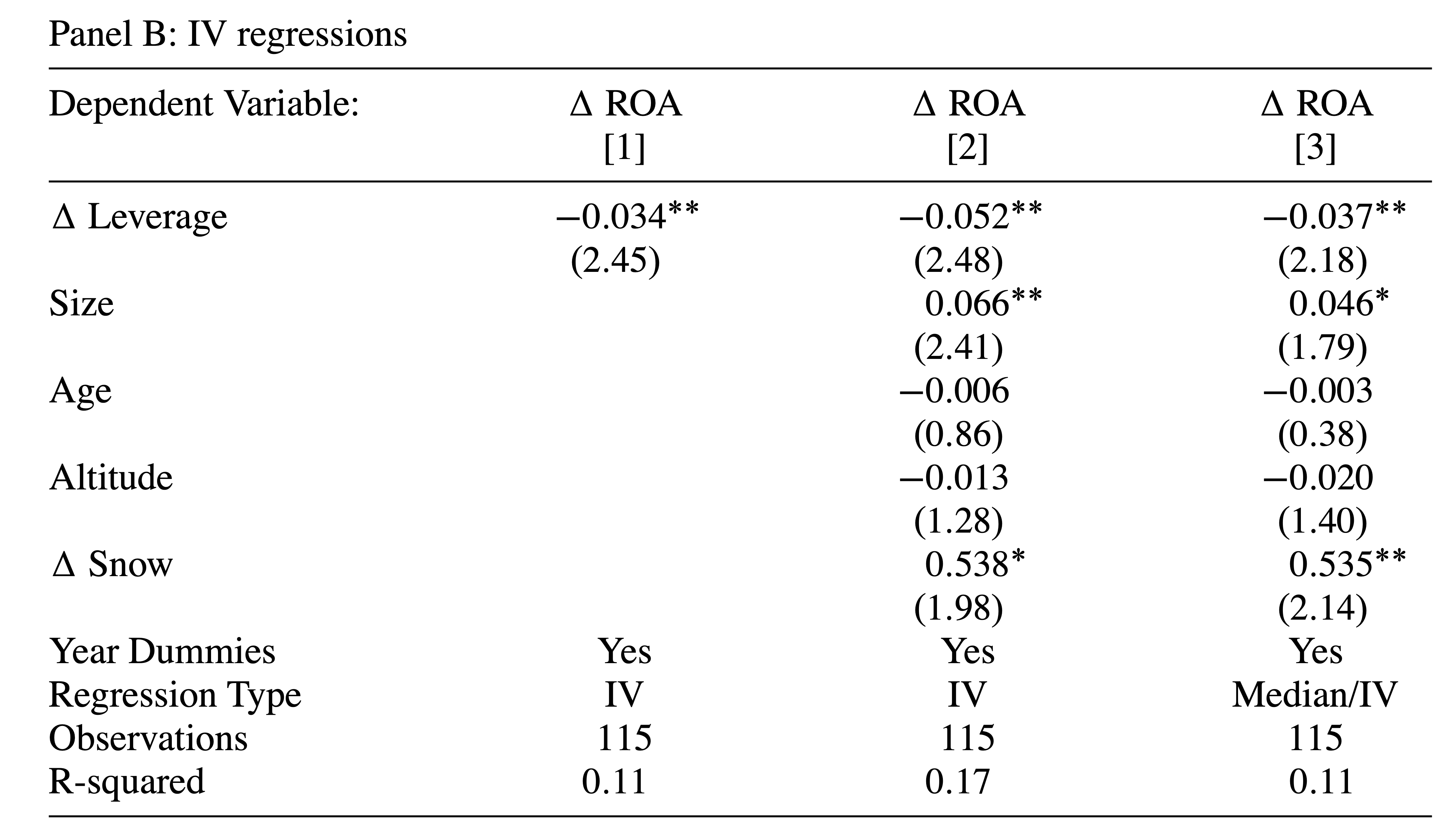
Ensuite, ils instrumentent le changement d’effet de levier par une neige anormalement élevées ou faibles au cours des dernières années
Enfin, ils montrent les résultats de la deuxième étape
Estimation IV
Le coefficient est négatif — conforme à la justification économique de l’instrument
La corrélation est forte — F-Stat de \beta=0 est 10,3 — Important pour s’assurer que la condition de pertinence est remplie
OLS
IV Deuxième Étape
Les résultats IV inversent le signe par rapport aux résultats MCO, suggérant que l’approche IV était importante
Les auteurs interprètent leurs résultats comme suggérant que la restructuration causée par des défauts stratégiques mène à un meilleur ROA car les gestionnaires/actionnaires sont mieux incités
Restriction d’exclusion et biais
Nous avons dit précédemment que l’hypothèse d’exclusion ne peut pas être testée
Nous n’observons jamais les vraies erreurs d’un modèle, nous ne pouvons donc pas tester si elles sont corrélées avec notre instrument
De plus, les résidus estimés seront toujours orthogonaux à toutes les covariables dans une régression, donc nous ne pouvons pas “tester” si une variable potentiellement endogène est corrélée avec l’erreur d’une régression
Les chercheurs doivent fournir des preuves soutenant que la restriction d’exclusion pourrait tenir
Puisque l’échantillon de GMSW est petit, le biais pourrait être un problème mais ils trouvent une VI qui est opposée au MCO et leur instrument est fort, c’est donc moins un problème (rappelez-vous que les petits écarts par rapport à l’exogénéité sont un problème avec de petits échantillons et des instruments faibles)
Derniers points sur les VI
La première étape doit être linéaire afin de garantir des estimations de deuxième étape cohérentes
Les variables endogènes binaires ne doivent PAS être estimées par probit/logit
Toutes les variables de la deuxième étape doivent être incluses dans la première étape, sinon les estimations sont incohérentes
L’inférence statistique dans le second stade doit être faite sur des données réelles (non estimées). (le module linearmodels le fait automatiquement)
I peut également être utilisé pour corriger une erreur de mesure s’il s’agit d’un problème et que vous disposez d’un instrument plausible
Bootstrap et Inférence par Randomisation
Motivation
Dans de nombreux contextes empiriques, l’inférence asymptotique standard peut être peu fiable :
Petits échantillons — les approximations asymptotiques peuvent ne pas tenir
Distributions non standard — les statistiques de test peuvent ne pas être normalement distribuées
Structures de dépendance complexes — les erreurs types peuvent être difficiles à calculer analytiquement
Les méthodes basées sur la simulation offrent une alternative en construisant la distribution d’une statistique de test empiriquement plutôt qu’en s’appuyant sur des approximations théoriques.
Voir Rosenbaum (2010) et Imbens and Rubin (2015) pour des discussions détaillées.
Inférence par Bootstrap
Le bootstrap(Efron 1979) estime la distribution d’échantillonnage d’une statistique en rééchantillonnant avec remplacement à partir des données observées.
Procédure :
Calculer la statistique d’intérêt \hat{\tau} à partir de l’échantillon original
Tirer B échantillons bootstrap (même taille, avec remplacement)
Calculer \tilde{\tau}_b pour chaque échantillon bootstrap b = 1, \ldots, B
Utiliser la distribution de \{\tilde{\tau}_1, \ldots, \tilde{\tau}_B\} pour l’inférence
Intervalles de confiance : Utiliser les quantiles de la distribution bootstrap, par ex. les 2,5e et 97,5e percentiles pour un IC à 95%.
p-values : Fraction des statistiques bootstrap au moins aussi extrêmes que \hat{\tau} sous l’hypothèse nulle.
Bootstrap — Intuition
L’idée clé : la distribution empirique \hat{F}(x) des données observées approxime la vraie distribution de la population F(x).
Tirer avec remplacement de l’échantillon équivaut à tirer de \hat{F}(x)
Chaque échantillon bootstrap reflète la variabilité que l’on attendrait si l’on pouvait rééchantillonner de la population
La distribution bootstrap de \tilde{\tau} approxime la distribution d’échantillonnage de \hat{\tau}
Fonctionne bien lorsque :
L’échantillon est représentatif de la population
La statistique est lisse (par ex. moyennes, coefficients de régression)
Peut échouer lorsque l’échantillon est très petit ou que la statistique dépend de valeurs extrêmes.
Inférence par Randomisation
L’inférence par randomisation (aussi appelée tests de permutation ou mélanges aléatoires) teste si une relation observée est statistiquement significative en brisant l’association entre les variables.
Procédure (par ex. tester si Y est lié à X) :
Calculer la statistique \hat{\tau} à partir des données originales \{Y_t, X_t\}
Mélanger aléatoirement \{Y_t\} (sans remplacement) pour créer \{\tilde{Y}_t\}
\tilde{Y}_t est maintenant indépendant de X_t
Calculer \tilde{\tau} à partir de \{\tilde{Y}_t, X_t\}
Répéter N fois pour obtenir \{\tilde{\tau}_1, \ldots, \tilde{\tau}_N\}
p-value : Rejeter si \hat{\tau} < q_{2{,}5\%}(\tilde{\tau}) ou \hat{\tau} > q_{97{,}5\%}(\tilde{\tau}).
Bootstrap vs. Inférence par Randomisation
Bootstrap
Randomisation
Rééchantillonnage
Avec remplacement
Sans remplacement (mélange)
Ce qu’il teste
Incertitude d’échantillonnage
Si la relation est réelle
Hypothèse nulle
Varie (par ex. \beta = 0)
Pas d’association entre les variables
Préserve
Distributions marginales
Distributions marginales, taille d’échantillon
Brise
Rien (rééchantillonne les paires)
L’association entre Y et X
Les deux méthodes sont non paramétriques : elles ne font aucune hypothèse sur la distribution des données.
Utiliser les deux fournit des preuves complémentaires : le bootstrap reflète l’incertitude d’échantillonnage, tandis que la randomisation teste la significativité structurelle.
Exemple : Bootstrap et Randomisation en MCO
Considérons un petit échantillon (n = 30) où nous estimons Y = \alpha + \beta X + \varepsilon.

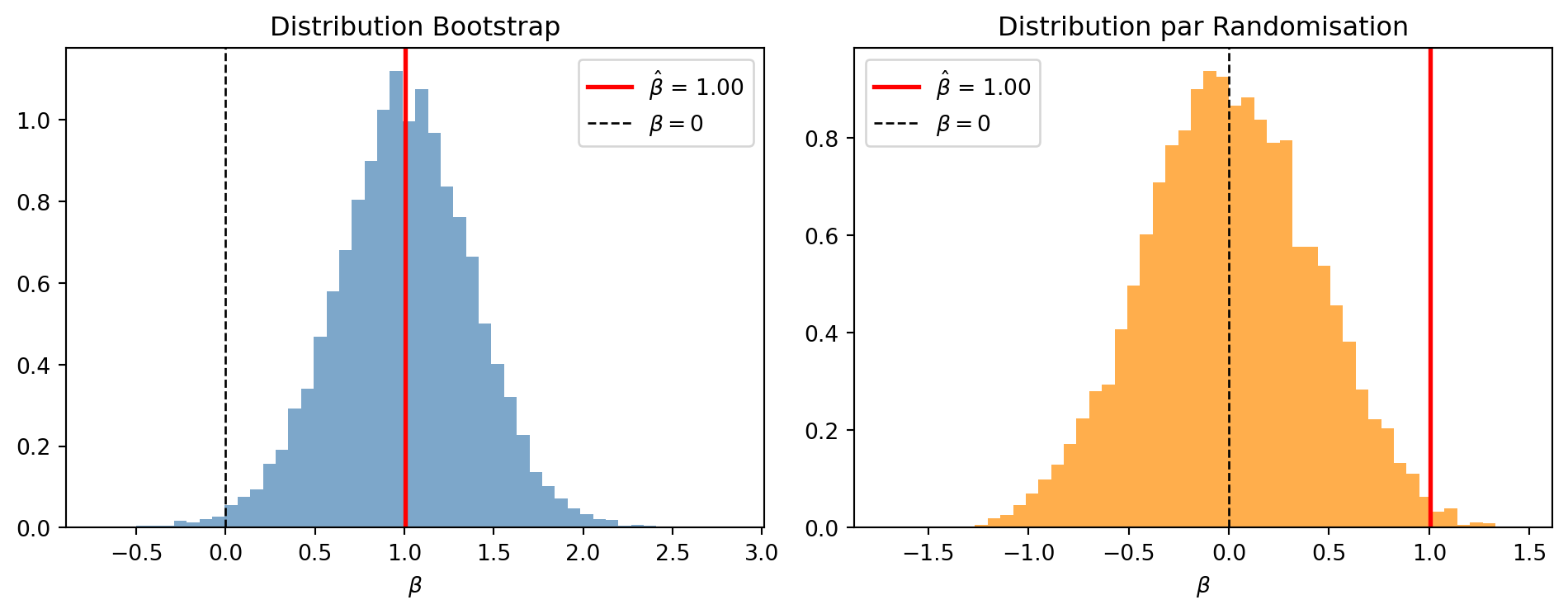
Comment cela fonctionne-t-il ?
Peut également être estimé en tant que système GMM
\widehat{\beta}_{2SLS} \overset{p}{\rightarrow} \frac{Cov[z,y]}{Cov[z,x]} = \beta + \frac{Cov[\epsilon,z]}{Cov[x,z]} \quad \text{lorsque} \quad T \rightarrow \infty