| exret | mktrf | smb | hml | |
|---|---|---|---|---|
| date | ||||
| 2023-01-03 | -0.020630 | -0.0048 | 0.0008 | -0.0012 |
| 2023-01-04 | 0.030148 | 0.0081 | 0.0054 | 0.0005 |
| 2023-01-05 | -0.032986 | -0.0114 | -0.0018 | 0.0122 |
| 2023-01-06 | 0.041470 | 0.0221 | -0.0006 | 0.0005 |
| 2023-01-09 | 0.051583 | 0.0004 | 0.0054 | -0.0124 |
| 2023-01-10 | 0.017811 | 0.0080 | 0.0091 | -0.0056 |
| 2023-01-11 | 0.005613 | 0.0126 | 0.0017 | -0.0082 |
| 2023-01-12 | 0.031703 | 0.0046 | 0.0145 | -0.0030 |
| 2023-01-13 | 0.023329 | 0.0046 | 0.0028 | -0.0029 |
| 2023-01-17 | 0.047348 | -0.0018 | 0.0017 | -0.0052 |
MATH60230 - Séance 7
Plan
- Régression linéaire
- Révision de la régression linéaire
- Erreurs Standards robustes
- Erreurs de mesure
- Variables indicatrices
- Numpy
Régression linéaire
Nous écrivons les régressions linéaires comme
y_{t}=X_{t}\beta+\varepsilon_{t}
où \varepsilon_{t} est un terme d’erreur et E\left( \varepsilon_{t}\right) =0, X_t est un vecteur de variables aléatoires, et \beta est un vecteur de coefficients. S’il y a un intercept (\alpha), alors la première variable de X_t est une constante égale à un et le premier coefficient de \beta est \alpha.
- Nous sélectionnons \beta pour minimiser
\begin{aligned} E\left[ \left( y_{t}-X_{t}\beta\right) ^{2}\right] &= E\left[ \varepsilon_{t}^{2}\right] \\ \Rightarrow \frac{d}{d\beta} E\left[ \left( y_{t}-X_{t}\beta\right) ^{2}\right] &= 0 \end{aligned}
- Le \beta^{*} qui résout ce problème est \beta^{*} = E\left[ X_t^{\prime}X_t\right]^{-1}\cdot E\left[ X_t^{\prime}y_t \right]
Régression linéaire
WLLN
T^{-1}\sum_{t=1}^{T}X_{t}^{\prime}y_{t}\rightarrow E\left( X_{t}^{\prime}y_{t}\right) \text{ et }T^{-1}\sum_{t=1}^{T}X_{t}^{\prime}X_{t}\rightarrow E\left[ X_{t}^{\prime}X_{t}\right]
En pratique, nous remplaçons E\left( X_{t}^{\prime}X_{t}\right) et E\left( X_{t}^{\prime}y_{t}\right) par leurs estimations d’échantillon fini
\widehat{\beta}=\left( \frac{1}{T}\sum_{t=1}^{T}X_{t}^{\prime}X_{t}\right)^{-1}\left( \frac{1}{T}\sum_{t=1}^{T}X_{t}^{\prime}y_{t}\right) =\left( X^{\prime}X\right) ^{-1}\left( X^{\prime}y\right)
où X est la matrice T\times K dont la t-ème ligne est X_{t} et y est le vecteur dont l’élément t est y_{t}.
Régression linéaire
X = \left[\begin{array}{cccccc} 1 & x_{1, 1} & x_{2, 1} & \cdots & x_{K-2, 1} & x_{K-1, 1} \\ 1 & x_{1, 2} & x_{2, 2} & \cdots & x_{K-2, 2} & x_{K-1, 2} \\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 1 & x_{1, T-1} & x_{2, T-1} & \cdots & x_{K-2, T-1} & x_{K-1, T-1} \\ 1 & x_{1, T} & x_{2, T} & \cdots & x_{K-2, T} & x_{K-1, T} \end{array} \right]
y = \left[\begin{array}{c}y_1\\ y_2\\ \vdots\\ y_{T-1}\\ y_T \end{array} \right], \quad \beta = \left[\begin{array}{c}\alpha \\ \beta_1 \\ \beta_2 \\ \vdots \\ \beta_{K-2} \\ \beta_{K-1} \end{array} \right]
Exemple
Régressons NVDA sur les 3 facteurs de Fama and French (1995)
r_{\text{NVDA},t}-r_{f,t} = \alpha + \beta_1(r_{\text{M},t}-r_{f,t}) + \beta_2SMB_t + \beta_3HML_t + \beta_4MOM_t + \varepsilon_t
Régression univariée
| Dep. Variable: | exret | R-squared: | 0.290 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.287 |
| Method: | Least Squares | F-statistic: | 101.1 |
| Date: | Sun, 25 Jan 2026 | Prob (F-statistic): | 3.65e-20 |
| Time: | 15:31:40 | Log-Likelihood: | 560.91 |
| No. Observations: | 250 | AIC: | -1118. |
| Df Residuals: | 248 | BIC: | -1111. |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0.0036 | 0.002 | 2.230 | 0.027 | 0.000 | 0.007 |
| mktrf | 1.9041 | 0.189 | 10.052 | 0.000 | 1.531 | 2.277 |
| Omnibus: | 224.272 | Durbin-Watson: | 2.030 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 7220.673 |
| Skew: | 3.332 | Prob(JB): | 0.00 |
| Kurtosis: | 28.471 | Cond. No. | 116. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Régression univariée
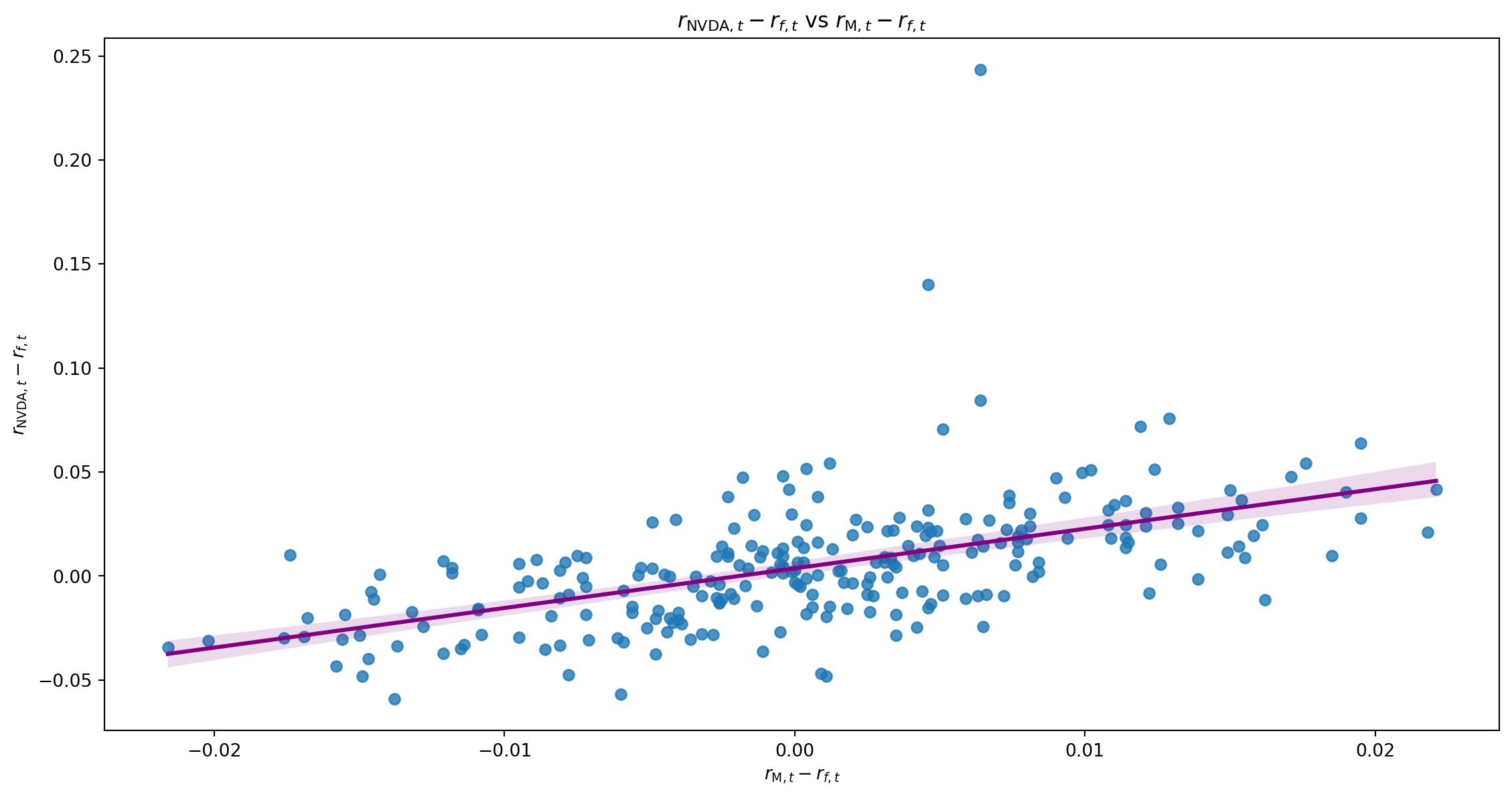
Régression univariée
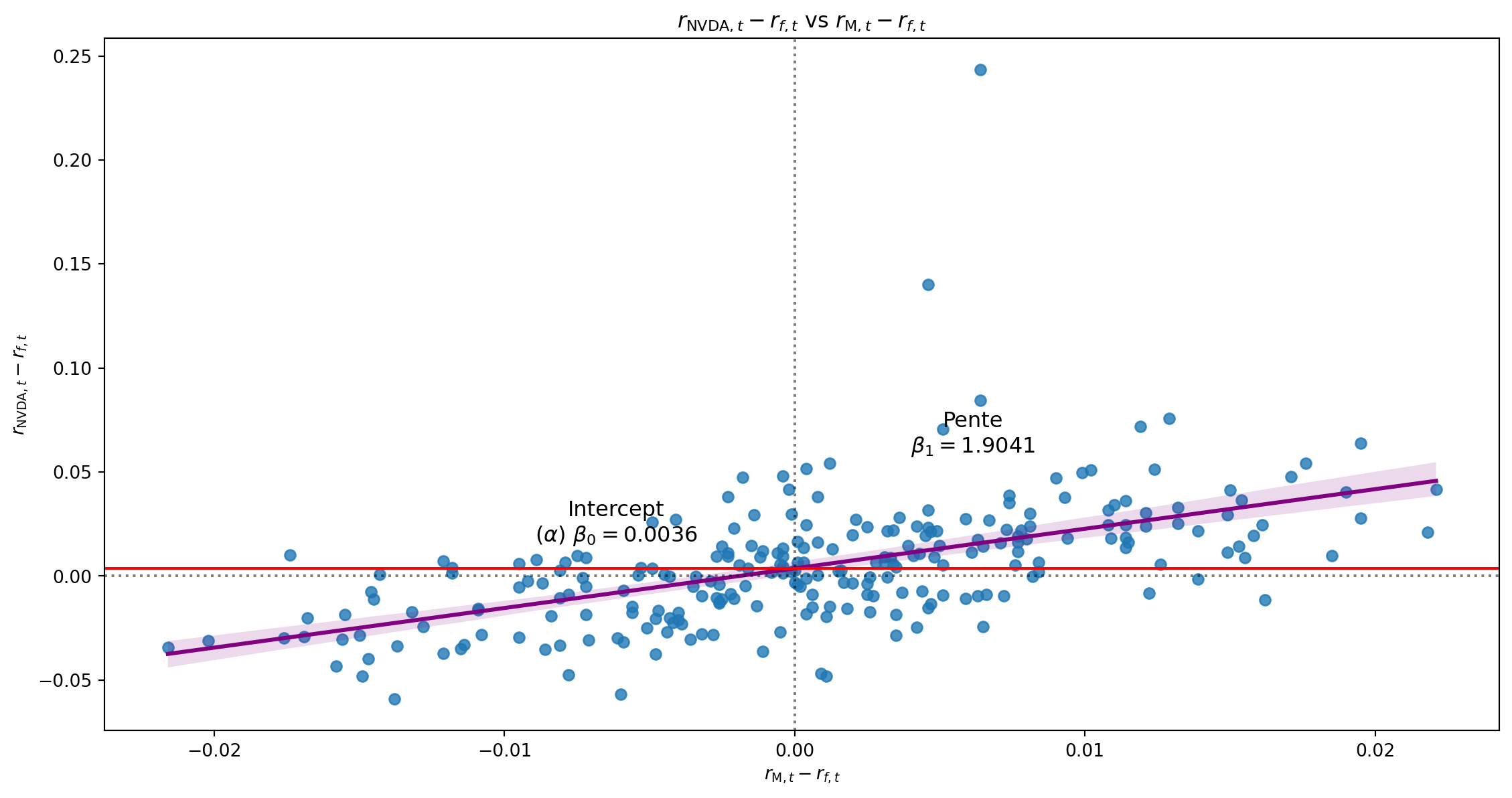
Résidus
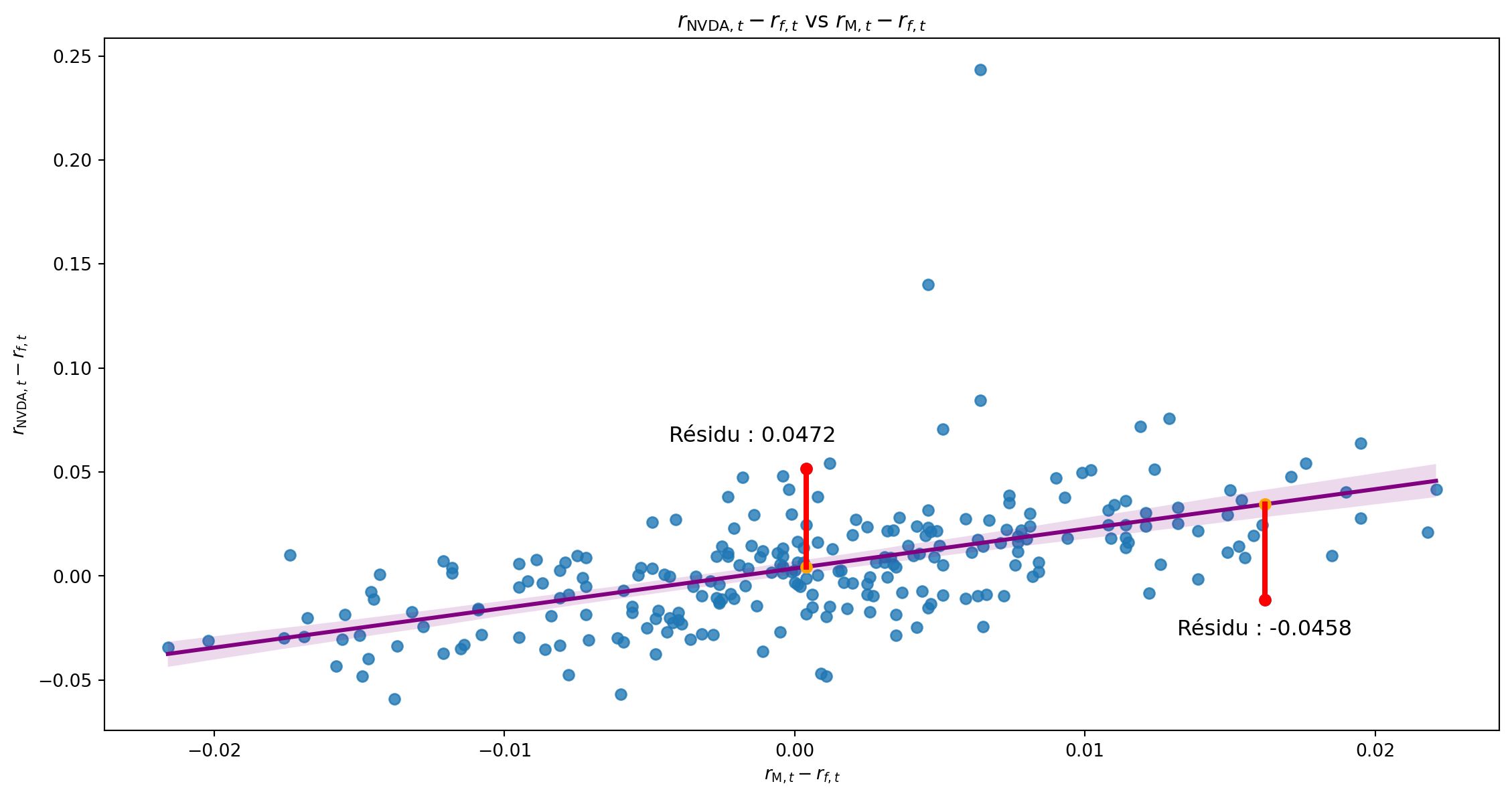
Impact des valeurs extrêmes
Impact des valeurs extrêmes
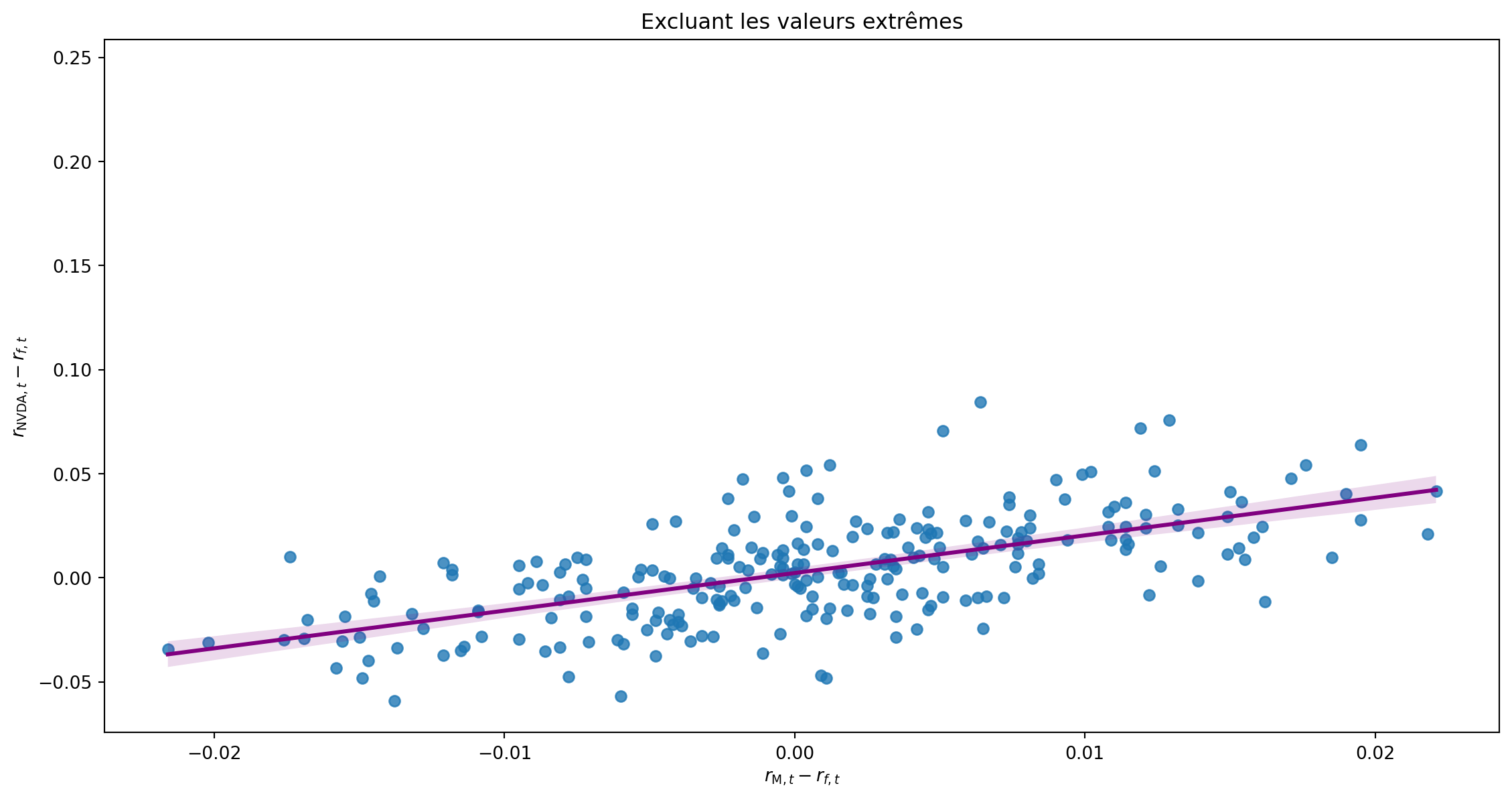
Régression multivariée
| Dep. Variable: | exret | R-squared: | 0.382 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.374 |
| Method: | Least Squares | F-statistic: | 50.61 |
| Date: | Sun, 25 Jan 2026 | Prob (F-statistic): | 1.63e-25 |
| Time: | 15:31:41 | Log-Likelihood: | 578.28 |
| No. Observations: | 250 | AIC: | -1149. |
| Df Residuals: | 246 | BIC: | -1134. |
| Df Model: | 3 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0.0031 | 0.002 | 2.020 | 0.044 | 7.73e-05 | 0.006 |
| mktrf | 2.0029 | 0.192 | 10.436 | 0.000 | 1.625 | 2.381 |
| smb | -0.5142 | 0.249 | -2.069 | 0.040 | -1.004 | -0.025 |
| hml | -1.0495 | 0.206 | -5.091 | 0.000 | -1.456 | -0.644 |
| Omnibus: | 223.511 | Durbin-Watson: | 2.103 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 7528.349 |
| Skew: | 3.293 | Prob(JB): | 0.00 |
| Kurtosis: | 29.064 | Cond. No. | 180. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Régression linéaire
\widehat{\beta} est l’estimation des Moindres Carrés Ordinaires (MCO) de \beta
Les estimateurs MCO minimisent la variance des résidus \widehat{\varepsilon}_{t}=y_{t}-X_{t}\widehat{\beta}
Cela n’implique pas que \widehat{\beta} est toujours le meilleur estimateur de \beta
Le théorème de Gauss-Markov : Sous certaines conditions
- \widehat{\beta} est le Meilleur Estimateur Linéaire Non Biaisé de \beta
\Rightarrow MCO est BLUE
Pour savoir quand utiliser les MCO, vous devez savoir quand le théorème de Gauss-Markov s’applique !
Le théorème de Gauss-Markov
E\left[ \varepsilon|X\right] =0 (Orthogonalité)
- \beta capture tous les effets systématiques de X sur y
\Rightarrow les résidus ne contiennent aucune information pertinente sur X - Cela nous permet d’identifier \beta et de distinguer son effet de celui de \varepsilon
- Tous les estimateurs que nous étudions nécessitent une condition similaire pour l’identification
- \beta capture tous les effets systématiques de X sur y
E\left[ X^{\prime}y\right] et E\left[ X^{\prime}X\right] existent
- Cela peut ne pas être vrai pour des distributions avec des queues suffisamment larges
- E\left[ X^{\prime}X\right]: X non stationnaire ?
E\left[ X^{\prime}X\right] ^{-1} existe.
- X^{\prime}X doit être de plein rang
- sinon les éléments individuels de \beta peuvent ne pas être identifiés
- Les erreurs \varepsilon sont homoscédastiques : \forall t, s\quad E[\varepsilon^2_t] = E[\varepsilon^2_s]
Le théorème de Gauss-Markov
Si ces conditions sont satisfaites, le Théorème de Gauss-Markov prouve que \widehat{\beta} est le meilleur estimateur non biaisé de \beta qui est linéaire en \varepsilon
\begin{aligned} \widehat{\beta} &=\left( X^{\prime}X\right) ^{-1}X^{\prime}y\\ &= \left( X^{\prime}X\right) ^{-1}X^{\prime}\left( X\beta+\varepsilon \right)\\ &=\beta+\left( X^{\prime}X\right) ^{-1}X^{\prime}\varepsilon \end{aligned}
Si \varepsilon n’est pas homoscédastique, \widehat{\beta} reste non biaisé, mais a une variance plus élevée.
- Cela signifie que \widehat{\beta} a la plus faible variance de tous les estimateurs non biaisés de la forme
\widehat{\beta}=\beta+w^{\prime}\varepsilon
Cela implique également que \omega^{\prime}\widehat{\beta} est le BLUE de \omega^{\prime}\beta
Comprendre la régression multiple
Interprétation de \beta_{i}: C’est l’effet de X_{i} sur y ceteris paribus (en maintenant tout le reste constant)
Dans le cas où X_{i} est corrélé avec d’autres régresseurs (par exemple X_{j}), cela ne prend pas en compte l’effet indirect de X_{i} sur y via X_{j}
Interprétation de \widehat{\beta}_{i}: Comprendre une manière alternative d’estimer \widehat{\beta}_{i}
Régressez y sur toutes les autres variables X_{j}\neq X_{i} et gardez les résidus \widehat{\varepsilon}_{y}.
Régressez X_{i} sur toutes les autres variables X_{j}\neq X_{i} et gardez les résidus \widehat{\varepsilon}_{x}.
\widehat{\beta}_{i} est le coefficient de la régression de \widehat{\varepsilon}_{y} sur \widehat{\varepsilon}_{x}
Cela montre que \widehat{\beta}_{i} capture l’effet de X_{i} sur y qui ne peut être expliqué par aucune autre variable X_{j}.
La variance des estimateurs des MCO
Quelle est la fiabilité des estimations MCO ? \begin{aligned} E\left( \widehat{\beta}\right) &=\beta+E\left( \left( X^{\prime}X\right) ^{-1}X^{\prime}\varepsilon\right) =\beta\\ Var\left( \widehat{\beta}\right) &=Var\left( \left( X^{\prime}X\right) ^{-1}X^{\prime}\varepsilon\right) =\sigma_{\varepsilon}^{2}\cdot\left( X^{\prime}X\right) ^{-1} \end{aligned}
- Si X est stochastique, ces formules donnent la moyenne et la variance de \widehat{\beta} conditionnellement à X.
Quelles sont les implications d’un
- changement d’échelle (par exemple, unités de mesure) de X ?
- la dispersion de X ?
Pour estimer \sigma_{\varepsilon}^{2} : \quad\widehat{\sigma}_{\varepsilon}^{2}=\frac{\widehat{\varepsilon}^{\prime}\widehat{\varepsilon}}{T-K}=\frac{1}{T-K}\sum_{t=1}^{T}\widehat{\varepsilon}_{t}^{2}=\frac{1}{T-K}\sum_{t=1}^{T}\left( y_{t}-X_{t}\widehat{\beta}\right)^{2}
Inférence sur les estimations MCO
Si \varepsilon_{t}\sim N\left( 0,\sigma_{\varepsilon}^{2}\right) i.i.d, alors \widehat{\beta}\sim N\left(\beta,\sigma_{\varepsilon}^{2}\left( X^{\prime}X\right)^{-1}\right)
Si \varepsilon_{t} n’est pas gaussien mais est toujours i.i.d\left( 0,\sigma_{\varepsilon}^{2}\right), \text{CLT} \Rightarrow \widehat{\beta}\rightarrow N\left(\beta,\sigma_{\varepsilon}^{2}\left(X^{\prime}X\right)^{-1}\right) \text{ quand } T\rightarrow\infty
Les éléments diagonaux de \sigma_{\varepsilon}^{2}\left( X^{\prime}X\right)^{-1} donnent la variance des éléments de \widehat{\beta}.
Pour tester H_{0}:\beta_{i}=\beta_{0,i} où \beta_{i} est le i-ème élément de \beta, nous pouvons utiliser le test t de Student \widehat{z}\equiv\left( \widehat{\beta}_{i}-\beta_{0,i}\right) / \sqrt{\left[ \widehat{\sigma}_{\varepsilon}^{2}\left( X^{\prime}X\right)^{-1}\right] _{\left[ i,i\right] }}\sim t\left( T-K\right)
T\rightarrow\infty\Rightarrow t\left( T-K\right) \rightarrow N\left( 0,1\right)
Inférence sur les estimations MCO
Supposons maintenant que nous voulons tester plusieurs restrictions de coefficients conjointement ?
- H_{0}:R\cdot\beta=b où R est une matrice q\times K et b est un vecteur q\times1
Si \widehat{\beta}\sim N\left(\beta,\Sigma\right) où \Sigma \equiv\sigma_{\varepsilon}^{2}\left( X^{\prime}X\right)^{-1}
\Rightarrow\left(R\cdot\widehat{\beta}-b\right) \sim N\left(0, R^{\prime}\cdot\Sigma\cdot R\right) sous H_{0}
\Rightarrow \mathcal{F} \equiv\left( R\cdot\widehat{\beta}-b\right) ^{\prime}\cdot\left[ R\cdot\Sigma\cdot R^{\prime}\right]^{-1}\cdot\left( R\cdot\widehat{\beta}-b\right) \cdot q^{-1} \sim F\left(q, T-K\right) sous H_{0} où q est le nombre de restrictions (rang de R) et K est le nombre de paramètres estimés (# éléments de \beta)
Notez que \mathcal{F} =\frac{SSR_{R}-SSR_{U}}{SSR_{U}}\cdot\frac{T-K}{q}
où
SSR_{i}\equiv\widehat{\varepsilon}_{i}^{\prime}\cdot \widehat{\varepsilon}_{i}
\begin{aligned}
i&=U\Rightarrow \text{régression non restreinte}\\
i&=R\Rightarrow \text{régression restreinte}
\end{aligned}
Test F par défaut
y = \alpha + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \varepsilon = [1\ x_1\ x_2\ x_3] [\alpha\ \beta_1\ \beta_2\ \beta_3\ ]^{\prime}
- Le test F est un test de la signification conjointe d’un groupe de variables
- La H_0 “par défaut” est que tous les coefficients \beta sont nuls :
H_{0}:R\cdot\beta=b \Rightarrow \underbrace{\left[\begin{array}{cccc}0 & 1 & 0 & 0\\0 & 0 & 1 & 0\\0 & 0 & 0 & 1\\ \end{array} \right]}_{R} \left[\begin{array}{c}\alpha \\ \beta_1 \\ \beta_2 \\ \beta_3 \end{array} \right] = \underbrace{\left[\begin{array}{c}0 \\ 0 \\ 0 \end{array} \right]}_{b}
Comprendre le test F
y = \alpha + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \varepsilon = [1\ x_1\ x_2\ x_3] [\alpha\ \beta_1\ \beta_2\ \beta_3\ ]^{\prime}
- Plus généralement, H_0 peut être n’importe quelle combinaison linéaire des coefficients
- Supposons que nous voulons tester H_0: \beta_1 - \beta_2 = 2\beta_3 \text{ et } \beta_1 - 1 = \beta_2 \text{ et } \alpha = 0
Pour trouver R et b, nous pouvons écrire les restrictions comme :
\begin{aligned} \beta_1 - \beta_2 - 2\beta_3 &= 0\\ \beta_1 - \beta_2 &= 1\\ \alpha &= 0 \end{aligned}
H_{0}:R\cdot\beta=b \Rightarrow \underbrace{\left[\begin{array}{cccc}0 & 1 & -1 & -2\\0 & 1 & -1 & 0\\1 & 0 & 0 & 0\\ \end{array} \right]}_{R} \left[\begin{array}{c}\alpha \\ \beta_1 \\ \beta_2 \\ \beta_3 \end{array} \right] = \underbrace{\left[\begin{array}{c}0 \\ 1 \\ 0 \end{array} \right]}_{b}
Erreurs standards robustes
Problème
Comment tester des hypothèses lorsque les erreurs ne sont pas indépendantes ?
Jusqu’à présent, nous n’avons parlé que de l’inférence lorsque les erreurs sont i.i.d.
- Que se passe-t-il si les erreurs ne sont pas du bruit blanc ?
- Que se passe-t-il si les erreurs sont hétéroscédastiques ?
L’approche moderne repose sur deux méthodes introduites dans les années 1980.
Chacune de ces méthodes est une correction non paramétrique : elles ne nécessitent pas que nous spécifiions une forme exacte de l’hétéroscédasticité (ou autocorrélation).
Elles sont très, très largement utilisées, en particulier en finance.
- Lars Peter Hansen a remporté le prix Nobel en 2013 pour la théorie derrière l’inférence HAC.
Erreurs standards robustes
Considérez le cas de
y_{t} =X_{t}\cdot\beta+e_{t}
E\left( e_{t}|X_{t}\right) =0
où e_{t} peut souffrir de l’un ou des deux problèmes ci-dessus.
Supposons que nous estimons \widehat{\beta} par MCO.
Normalement, nous utiliserions
\operatorname{Cov}\left( \widehat{\beta}\right)_{OLS}=\widehat{\sigma}_{e}^{2}\cdot\left( X^{\prime}X\right)^{-1}
Erreurs standards robustes
Erreurs standards de White
Remplacez \operatorname{Cov}( \widehat{\beta})_{OLS} par
\operatorname{Cov}\left( \widehat{\beta}\right)_{HC}=\left( X^{\prime}X\right)^{-1}\cdot\left[ X^{\prime}\cdot\operatorname*{diag}\left( \widehat{e}_{t}^{2}\right) \cdot X\right] \cdot\left( X^{\prime}X\right)^{-1}
Cela donne un estimateur de \operatorname{Cov}( \widehat{\beta})_{OLS} qui est robuste à l’hétéroscédasticité.
Notez que :
- X est T\times K
- \operatorname*{diag}\left( \widehat{e}_{t}^{2}\right) est une matrice T\times T avec des zéros partout sauf sur la diagonale principale, qui a un élément typique \widehat{e}_{j}^{2} dans la ligne j, colonne j
- L’équation (2.49) dans Tsay ajuste cela par \frac{T}{T-K} pour un meilleur rendement d’échantillon fini. (Avertissement : X_{t}^{\prime}= ma X_{t})
- White fait référence au professeur Hal White de l’UCSD, qui l’a proposé pour la première fois (voir White 1980)
Erreurs standards robustes
Erreurs standards HAC
Remplacez \left[ X^{\prime}\cdot\operatorname*{diag}( \widehat{e}_{t}^{2}) \cdot X\right] dans \operatorname{Cov}( \widehat{\beta})_{HC}
par \left[ X^{\prime}\cdot\operatorname*{diag}\left( \widehat{e}_{t}^{2}\right) \cdot X\right] + \sum_{j=1}^{l}\omega\left( j\right) \cdot\sum_{t=j+1}^{T}\left(X_{t}\widehat{e}_{t}\widehat{e}_{t-j}X_{t-j}^{\prime}+X_{t-j}\widehat{e}_{t-j}\widehat{e}_{t}X_{t}^{\prime}\right) où
- X_{t} est un vecteur K\times1, donc X_{t}\widehat{e}_{t}\widehat{e}_{t-j}X_{t-j}^{\prime}=\left( \widehat{e}_{t}\widehat{e}_{t-j}\right) \cdot X_{t}X_{t-j}^{\prime} est K\times K
- l est appelé un décalage de troncature (ou une bande passante)
- \omega\left( j\right) est une fonction de pondération (ou noyau) telle que \omega\left( 0\right) =1, \omega\left( j\right) =\omega\left( -j\right) et \omega\left( j\right) \rightarrow 0 lorsque \left\vert j\right\vert \rightarrow l
Cela donne une estimation de \operatorname{Cov}( \widehat{\beta})_{OLS} qui est robuste à l’hétéroscédasticité et à l’autocorrélation (HAC en anglais).
Erreurs standards robustes
Les Erreurs Standards HAC nécessitent que nous choisissions à la fois l et \omega\left( j\right) et ce choix pourrait affecter nos résultats.
- Les choix pour l sont presque toujours ad hoc et garantissent que l est une petite fraction de T.
- Une bonne pratique est de vérifier que l’utilisation de 0.5l et 2l ne change pas vos conclusions.
- Si les effets saisonniers pouvaient causer des autocorrélations, une autre règle empirique est de s’assurer que l\geq2f où f\equiv le nombre de périodes par cycle saisonnier (par exemple, f=4 pour des données trimestrielles, f=5 ou 7 pour des données journalières avec des modèles hebdomadaires, etc.)
- Il existe des problèmes connus sérieux avec les erreurs standards HAC dans certains (rares) cas avec des erreurs fortement négativement autocorrélées.
Erreurs standards robustes
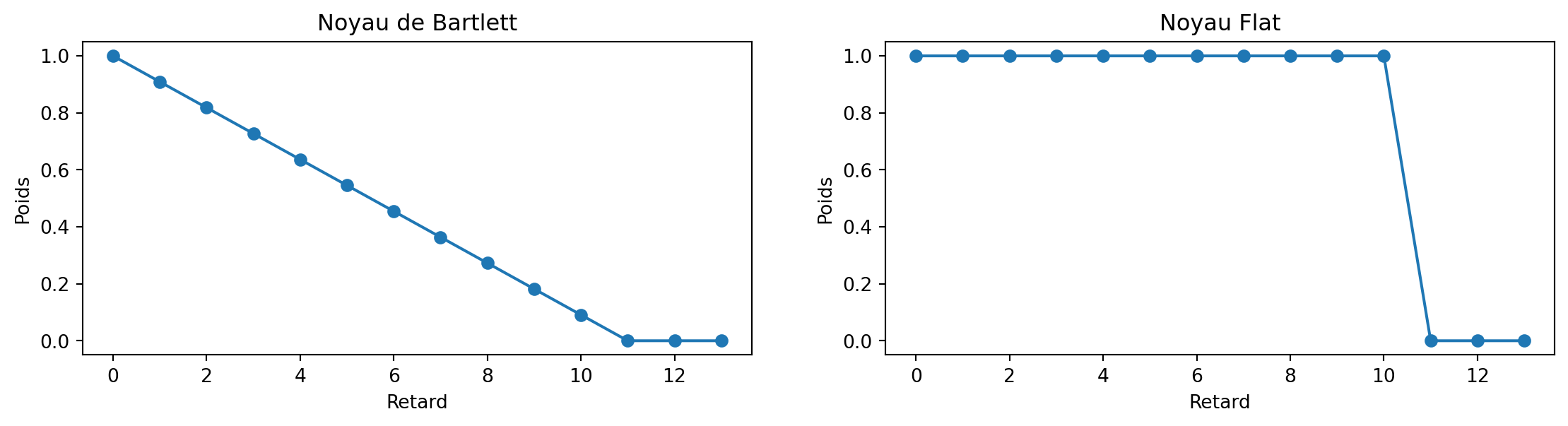
Il existe de nombreux choix populaires pour \omega\left( j\right)
Flat \omega\left( j\right) =1\left( j\leq l\right) : Selon Hansen and Hodrick (1980). Correction populaire pour les erreurs de prévision de périodes qui se chevauchent. Choisissez l=h-1 ; \operatorname{Cov} ( \widehat{\beta})_{HAC} pourrait ne pas être PSD
Bartlett \omega\left( j\right) =1-\frac{j}{l+1} : Selon Newey and West (1987). Le choix général le plus populaire \Longrightarrow \operatorname{Cov}( \widehat{\beta})_{HAC} toujours PSD
Erreurs de mesure
Supposons que le modèle “vrai” soit y_{t}=X_{t}\cdot\beta+\varepsilon_{t} \qquad\text{où}\qquad E\left( X_{t}\cdot\varepsilon_{t}\right) =0
Nous observons y_{t}, mais X_{t} nous ne l’observons qu’avec une erreur
- Au lieu du vrai X_{t}, nous avons \widetilde{X}_{t}=X_{t}+u_{t}
Si les erreurs de mesure sont des “bruits” dans le sens que
E\left[ X_{t}\cdot u_{t}\right] =E\left[ \varepsilon_{t}\cdot u_{t}\right] =0
\widetilde{X}_{t}=X_{t}+u_{t} \Rightarrow E\left[ \widetilde{X}_{t}\cdot u_{t}\right] \neq 0
Cela est généralement appelé un problème d’erreur de mesure.
Erreurs de mesure
- Que se passe-t-il si nous régressons maintenant y_{t} sur \widetilde{X}_{t} ?
\begin{aligned} y_{t} &=\widetilde{X}_{t}\cdot\beta+e_{t}\\ &= X_{t}\cdot\beta+u_{t}\cdot\beta+e_{t}\\ &= X_{t}\cdot\beta+\varepsilon_{t} \end{aligned}
Donc évidemment, e_{t}=\varepsilon_{t}-\beta\cdot u_{t}
- Donc E\left[\widetilde{X}_{t}\cdot e_{t}\right] =E\left[\widetilde{X}_{t}\cdot\left(\varepsilon_{t}-\beta\cdot u_{t}\right)\right] = -\beta\cdot E\left[\widetilde{X}_{t}\cdot u_{t}\right] \neq 0
\Rightarrow e_{t} viole l’une des conditions du théorème de Gauss-Markov pour la régression y_{t}=\widetilde{X}_{t}\beta+e_{t}
Erreurs de mesure
- \Rightarrow \widehat{\beta}=\left( \widetilde{X}^{\prime}\widetilde{X}\right)^{-1}\widetilde{X}\cdot y sera biaisé
E\left( \widehat{\beta}\right) =\beta\frac{\sigma_{X}^{2}}{\sigma_{X}^{2}+\sigma_{u}^{2}}
\Rightarrow \widehat{\beta} sous-estime généralement \beta
Erreurs de mesure
Supposons que nous régressons les rendements des actions sur les beta des actions estimés \widehat{\beta}_{i}^{\prime}s
- Les \widehat{\beta}_{i}^{\prime}s contiennent une certaine erreur d’estimation
- Nous devrions donc nous attendre à ce que les coefficients MCO de la régression soient plus petits que ce que les “vrais” \beta donneraient.
- Plus notre estimateur est imprécis, plus le biais vers le bas est important.
Que faire ?
- Obtenir des estimations plus précises de \beta pour réduire le biais.
- Trouver des “instruments valides” ; Z_{t} tels que
E\left( Z^{\prime}\widetilde{X}\right) \neq 0\text{ et }E\left( Z^{\prime}e_{t}\right) =0
et estimer en utilisant les moindres carrés en deux étapes (IV)
- Utiliser la méthode générale des moments (GMM)
Variables indicatrices
Définition : Une variable indicatrice (dummy) est une variable binaire que nous incluons comme variable indépendante dans une régression.
c’est-à-dire D_{t}\equiv1\left( Z_{t}\right) et nous modélisons y_{t}=\begin{bmatrix} X_{t} & D_{t} \end{bmatrix} \cdot\overrightarrow{\beta}+\varepsilon_{t}
De nombreuses utilisations courantes :
- Effets Temporels : D_{t}=1\left( t<t^{\ast}\right) ou D_{t}=1\left( t\in\left\{ \text{Janvier}\right\}\right)
- Événements : D_{t}=1\left( t\in\left\{ \text{Coupe de dividendes}\right\}\right) ou D_{t}=1\left( t\in\left\{ r_{t}<\text{VaR}_{5\%}\right\}\right)
- Caractéristiques : D_{i}=1\left( i\in\left\{ \text{Homme}\right\}\right) ou D_{i}=1\left( i\in\left\{ \text{cotée en bourse}\right\}\right)
Tester H_{0}:\beta_{D}=0 teste le changement dans la moyenne conditionnelle de y. Cependant, fréquemment, nous voulons tester pour des changements dans \beta.
- Tester \beta_{D}=0 dans
y_{t}=X_{t}\cdot\beta_X+ D_{t}\cdot\beta_D+ \left( X_{t}\cdot D_{t}\right) \cdot\beta_{XD}+\varepsilon_{t}
Comprendre les variables indicatrices
Soit
- r_{TSX,t} est le rendement de la Bourse de Toronto
- \mathcal{1}_{FOMC,t} est une variable dummy qui est 1 les jours d’annonces du Federal Open Market Committee et 0 les autres jours.
Si nous estimons
r_{TSX,t} = \alpha + \gamma \mathcal{1}_{FOMC,t} + \varepsilon_t,
nous estimons conjointement
\begin{array}{rlll} r_{TSX,t} &= \alpha &+ \varepsilon_t &\text{ les jours sans FOMC}, \\ r_{TSX,t} &= (\alpha + \gamma) &+ \varepsilon_t & \text{ les jours de FOMC}. \end{array}
Ainsi, \gamma est le changement de rendement moyen les jours de FOMC par rapport aux jours sans FOMC.
Comprendre les variables indicatrices
Soit également r_{SP500,t} être le rendement du S&P 500.
Si nous estimons
r_{TSX,t} = \alpha + \gamma \mathcal{1}_{FOMC,t} + \beta_1 r_{SP500,t}+ \beta_{D} r_{SP500,t} \times \mathcal{1}_{FOMC,t} + \varepsilon_t,
nous estimons conjointement
\begin{array}{rllll} r_{TSX,t} &= \alpha &+\beta_1 r_{SP500,t} &+ \varepsilon_t &\text{ les jours sans FOMC}, \\ r_{TSX,t} &= (\alpha + \gamma) &+ (\beta_1 + \beta_{D}) r_{SP500,t} &+ \varepsilon_t & \text{ les jours de FOMC}. \end{array}
Ainsi, \beta_{D} est le changement de sensibilité des rendements TSX par rapport aux rendements du S&P 500 les jours de FOMC par rapport aux jours sans FOMC.
Variables indicatrices
Erreur de débutant : Inclure une constante et un ensemble complet de variables dummy dans une régression.
- par exemple D_{t}^{1}\equiv1\left( t\in Q1\right);~D_{t}^{2}=1\left( t\in Q2\right),\ldots,D_{t}^{4}=1\left( t\in Q4\right)
Remarquez que D_{t}^{1}+D_{t}^{2}+D_{t}^{3}+D_{t}^{4}=1\quad\forall t.
\therefore Tout X avec les 4 variables indicatrices et une constante ne sera pas de plein rang.
\therefore \left( \frac{X^{\prime}X}{T}\right)^{-1} n’existe pas
Solution : Supprimez une des variables dummy.
- La constante dans la régression vous donne l’effet pendant les périodes où toutes les variables indicatrices =0
- Les coefficients estimés sur les variables indicatrices vous donnent la différence entre ces périodes de bases et les périodes représentées par les variables indicatrices.
Références
Baltagi, Badi H. 2022. Econometrics. 6th ed. Classroom Companion: Economics. Springer Cham. https://doi.org/10.1007/978-3-030-80149-6.
Fama, Eugene F, and Kenneth R French. 1995. “Size and Book-to-Market Factors in Earnings and Returns.” The Journal of Finance 50 (1): 131–55.
Hansen, Lars Peter, and Robert J Hodrick. 1980. “Forward Exchange Rates as Optimal Predictors of Future Spot Rates: An Econometric Analysis.” Journal of Political Economy 88 (5): 829–53. https://www.journals.uchicago.edu/doi/abs/10.1086/260910.
McKinney, Wes. 2022. Python for Data Analysis: Data Wrangling with Pandas, Numpy, and Jupyter. 3rd ed. O’Reilly Media. https://wesmckinney.com/book/.
Newey, Whitney K, and Kenneth D West. 1987. “A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix.” Econometrica 55 (3): 703–8. https://www.jstor.org/stable/1913610.
White, Halbert. 1980. “A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity.” Econometrica, 817–38. https://doi.org/10.2307/1912934.
![]()
MATH60230