MATH60230 - Séance 3
Plan pour aujourd’hui
- Survol des bases de données financières à HEC
- Analyse de données
- Introduction à pandas
- Démo d’utilisaton de pandas
- Function lambdas
- Devoir 3: pandas!
Bases de données financières à HEC Montréal
Site internet de la bibliothèque :
- Guide pour finance : https://libguides.hec.ca/Finance
- Liste complète : https://www.hec.ca/biblio/banques-de-donnees/index.html
De nombreuses bases de données sont disponibles via le portail WRDS
- En tant qu’étudiants gradués, vous pouvez obtenir un compte par l’intermédiaire de la bibliothèque.
Données de marché et d’entreprises
- Stations de travail Bloomberg
- CHASS CFMRC/TSX : Données boursières quotidiennes, marché canadien
- CRSP (via WRDS) : Données boursières quotidiennes + fonds communs de placement, marché américain
- TAQ (via WRDS) : Données boursières intrajournalières, marché américain
- TRACE (via WRDS) : Données obligataires intrajournalières, marché américain
- Compustat - Capital IQ (via WRDS) : Informations sur les entreprises, dirigeants, indices, etc.
- Trucost : Empreinte carbone des entreprises
Autres sources de données
Nouvelles
- Factiva
- Nexis Uni
Données publiques disponibles :
- Banque du Canada, Réserve fédérale américaine, etc.
- Groupes industriels
- Agences gouvernementales
L’analyse de données (1)
La première étape consiste à identifier la question de recherche et les hypothèses, puis à concevoir la méthodologie en fonction des données disponibles.
La disponibilité des données est souvent contraignante pour la recherche. Nous utiliserons souvent des données provenant de sources standards (ex: WRDS), mais elles peuvent aussi provenir d’autres sources (données privées, web, etc.) —
L’analyse de données (2)
Avant de faire toute analyse, nous devons connaître les données:
- Pour repérer les erreurs de données potentielles.
- Pour déterminer le format des données.
La première étape après le chargement des données devrait être de regarder les données:
- Données brutes (petit échantillon)
- Tracer des figures
- Calculer des statistiques descriptives
L’analyse de données (3)
- L’étape suivante est généralement le nettoyage des données.
- Souvent la partie la plus longue d’un projet empirique.
- Consiste à la conversion au format approprié, à l’alignement des données, à la fusion des différents ensembles de données, etc.
- La sortie est un ensemble de données prêt pour l’analyse.
- pandas est un excellent outil pour le nettoyage des données.
L’analyse de données (4)
- Une fois le jeu de données prêt, nous pouvons procéder à l’analyse et rapporter les résultats à l’aide de tableaux et de figures.
pandas
- pandas est un outil d’analyse et de manipulation de données open source rapide, puissant, flexible et facile à utiliser, construit sur le langage de programmation Python.
- Développé à l’origine par Wes McKinney alors qu’il travaillait chez AQR Capital Management.

pandas - Points forts
- Un objet DataFrame rapide et efficace pour la manipulation de données avec indexation intégrée
- Outils de lecture/écriture pour plusieurs formats
- Reformattage et pivotement flexibles
- Agrégation et transformation des données avec un puissant moteur de “group by”
- Fusion et jonction hautes performances d’ensembles de données
- Fonctionnalité des séries temporelles
pandas 2.0
- Principale nouveauté: Arrow engine (en plus de numpy)
- Supporte les valeurs manquantes pour le type de données entier
- Meilleur intégration avec l’écosystème Apache Arrow:
- Polars: Alternative à pandas, écrit en Rust.
- DuckDB: Base de données SQL en mémoire écrite en C++.
- ficheirs parquet: Format de stockage en colonnes. Pensez CSV, mais plus rapide et plus petit.
- Avertissement : version relativement récente (2023), pas toutes les autres bibliothèques sont compatibles avec les nouvelles fonctionnalités.
![]()
![]()
![]()
Data Wrangler : Intégration VS Code
- Data Wrangler est une extension VS Code qui fournit une interface utilisateur pour le nettoyage et la transformation des données.
- Il peut charger à partir d’un fichier ou d’un DataFrame pandas actif.
- Il fournit une interface visuelle pour filtrer, trier et transformer les données.
- Il peut générer du code Python pour reproduire les transformations.
Voir ma vidéo sur Data Wrangler pour une démo.
Démonstration !
Format large vs long
Format large (wide)
Chaque entité est une ligne, chaque période est une colonne.
date AAPL MSFT GOOGL
2024-01-01 0.012 0.008 0.015
2024-01-02 -0.005 0.003 0.002Utiliser pour : Opérations matricielles, corrélations, stats transversales.
Format long (tidy)
Chaque observation est une ligne distincte.
date ticker return
2024-01-01 AAPL 0.012
2024-01-01 MSFT 0.008
2024-01-02 AAPL -0.005Utiliser pour : Régressions, opérations groupées, filtrage.
Reformatage dans pandas
| Opération | Direction | Fonction pandas |
|---|---|---|
| Pivot | Long → Large | df.pivot() ou df.pivot_table() |
| Melt | Large → Long | df.melt() |
| Unstack | Index → Colonnes | df.unstack() |
| Stack | Colonnes → Index | df.stack() |
- Utilisez
pivot_table()lorsque vous avez des clés dupliquées (nécessite agrégation). - Polars :
df.pivot()etdf.unpivot().
Fonctions
- En Python, tout (presque) est un objet, y compris les fonctions.
- Cela signifie que vous pouvez passer une fonction comme paramètre à une autre fonction.
Détour : Estimation des dérivées
Estimation des dérivées
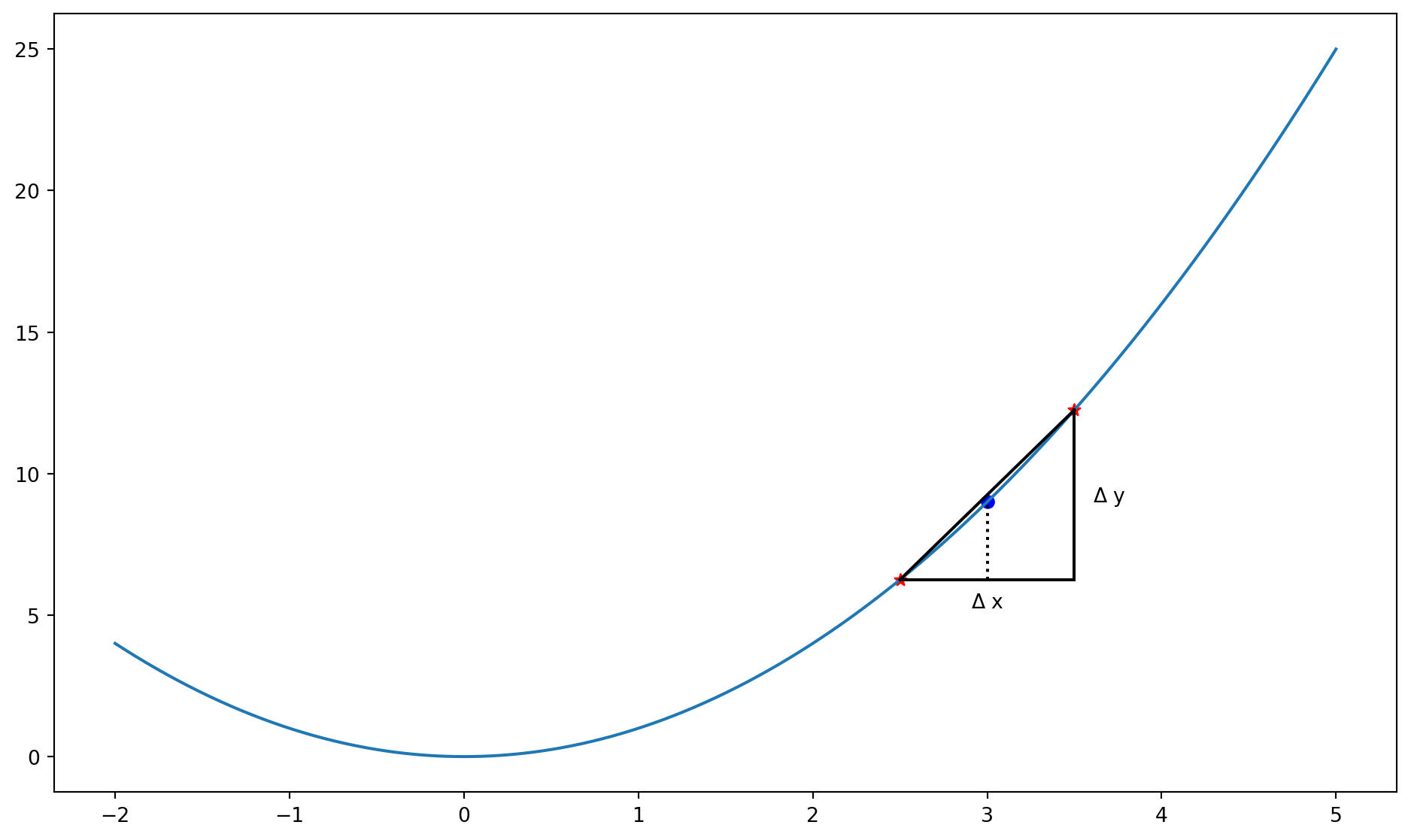
Estimer les dérivées numériquement
Considérons une fonction pour estimer la dérivée d’une autre fonction:
Supposons que nous ayons une fonction qui calcule le carré d’un nombre:
Exemple (2)
Vous pouvez maintenant passer square comme argument à deriv :
Note: \frac{\partial x^2}{\partial x} = 2x
Fonctions Lambda
- Pour les fonctions simples, les définir correctement avec
defpeut être exagéré. - À la place, nous utilisons des fonctions lambda (fonctions anonymes) :
- Celles-ci sont très utiles lorsqu’elles sont combinées avec la fonction
apply()dans pandas qui applique une fonction à chaque élément d’une série (une colonne).
Devoir 3
Pandas!
Prochaine séance
- Plus de pandas
- Jupyter Notebooks
![]()
MATH60230